第32章:Read最適化① 検索を速くする発想🔎🚀
今回は「一覧検索が遅い…😵💫」を、CQRSらしくスッキリ解決する回だよ〜!✨
ポイントは “Read側は表示のために好きな形に作り替えてOK” ってところ😊💕
この章のゴール🎯✨
学食アプリの「注文一覧」を例にして…
- 条件で絞り込み(例:ステータス、日付、キーワード)
- 並び替え(例:新しい順、金額順)
- ページング(例:20件ずつ)
…を サクサク動く ようにする考え方&実装の型を身につけるよ!🚀
1) まず結論:検索を速くする“3つのレバー”🔧✨
Read最適化って、だいたいこの3つをいじるだけで一気に改善するよ😊
-
データの形(Readモデル)を変える 📦✂️
画面に必要なものだけ持つ。必要なら「合計」「検索用文字列」みたいな加工済みも持つ。 -
インデックス(=高速道路)を貼る 🛣️🚗💨
よく使う検索条件に合わせて、DBに“近道”を作る。 -
クエリの形(取り方)を変える 🔎🧠
「全件取ってから絞る」じゃなく、「最初から絞って取る」「ページングを賢く」など。
2) “まずやっちゃダメ”例:全件なめてから絞る😇💥
最初にやりがちなのがこれ👇
- ① 全件読んで
- ② メモリ上で filter/sort して
- ③ 20件返す
データが増えると、検索のたびに全部なめることになるから一気に死ぬ…😵💫💦
CQRSのRead側は、ここを改善しやすいのが最高ポイントだよ✨
3) Read最適化の第一歩:検索パターンを“先に固定”する📝✨
「どんな検索が来るか」 を先に決めるのが超大事!
(ここが決まると、Readモデル&インデックスが自然に決まる😊)
例:注文一覧でよくあるやつ👇
- ステータス:
ORDERED / PAID / CANCELED - 期間:
createdAtの範囲 - キーワード:メニュー名・注文番号・ユーザー名(の一部)
- 並び:新しい順(
createdAt desc)が基本 - ページ:20件ずつ
この「よく使う検索セット」を “一軍” として扱うのがコツだよ🏆✨
4) Readモデルは「一覧の1行」単位で作ると強い💪📋
✅ 一覧用Readモデル(例)
「注文一覧の1行」に必要なものだけ持つ感じ👇
orderIdcreatedAtstatustotalPriceitemCountmenuNamesJoined(例:"唐揚げ丼, 味噌汁")searchText(検索用に整形した文字列)
ここでのコツは、画面が欲しい形を最優先にすること😊
ドメインモデルをそのまま返すのは卒業だよ〜🎓✨
5) “検索用フィールド”を用意すると強い🔎✨
検索って「LIKEで部分一致」だけに頼ると遅くなりがち…💦
なので 検索を速くするための加工済みカラム を持つのがRead側の勝ち筋だよ😊
例:searchText の作り方💡
- 小文字化(英字)
- 空白を統一
- 「注文番号」「メニュー名」「購入者名」をまとめて1本にする
6) インデックス超入門:どこに貼ればいいの?🛣️✨
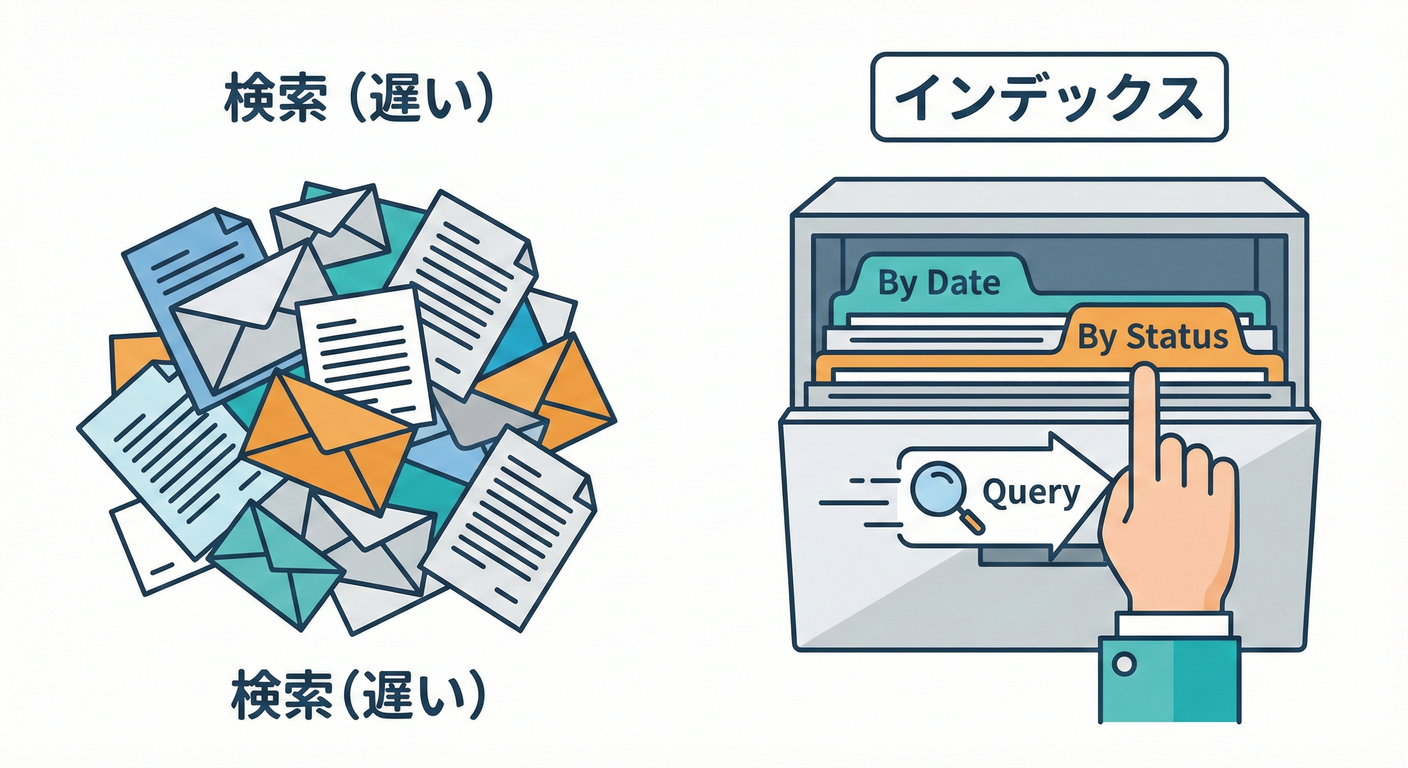
一番よく効くのはこれ👇
✅ 「絞り込み」+「並び替え」に合わせる
例:ステータスで絞って、新しい順に並べる
→ (status, createdAt) の複合インデックスが強い💪
Prismaなら @@index で作れるよ(公式ドキュメント)1
7) ハンズオンA:インメモリでも“インデックスっぽい発想”を体験しよ🧪✨
DBの前に、まず「索引を作ると速い」感覚を体験しちゃう😊
(DBのインデックスの気持ちがわかるやつ!)
7-1) 型を用意📦
type OrderStatus = "ORDERED" | "PAID" | "CANCELED";
type OrderListRow = {
orderId: string;
createdAt: number; // epoch millis にしちゃうと比較がラク😊
status: OrderStatus;
totalPrice: number;
itemCount: number;
menuNamesJoined: string;
searchText: string; // 例: "a-000123 からあげ丼 みそしる こみやんま"
};
type OrderListFilter = {
status?: OrderStatus;
createdFrom?: number;
createdTo?: number;
keyword?: string;
limit: number;
};
7-2) “索引(Map)”を持つストアを作る🗂️✨
export class OrderListStore {
private rows: OrderListRow[] = [];
// インデックスっぽいやつ✨
private byId = new Map<string, OrderListRow>();
private byStatus = new Map<OrderStatus, OrderListRow[]>();
upsert(row: OrderListRow) {
const existing = this.byId.get(row.orderId);
if (!existing) {
this.rows.push(row);
this.byId.set(row.orderId, row);
const bucket = this.byStatus.get(row.status) ?? [];
bucket.push(row);
this.byStatus.set(row.status, bucket);
return;
}
// 既存更新(雑にやるなら一回消して入れ直しでもOK😊)
this.remove(row.orderId);
this.upsert(row);
}
remove(orderId: string) {
const row = this.byId.get(orderId);
if (!row) return;
this.byId.delete(orderId);
this.rows = this.rows.filter(r => r.orderId !== orderId);
const bucket = this.byStatus.get(row.status) ?? [];
this.byStatus.set(row.status, bucket.filter(r => r.orderId !== orderId));
}
// “なるべく全件なめない”検索✨
query(filter: OrderListFilter): OrderListRow[] {
const source = filter.status
? (this.byStatus.get(filter.status) ?? [])
: this.rows;
const kw = filter.keyword?.trim().toLowerCase();
// createdAt desc で返す(安定してて気持ちいい😊)
return source
.filter(r => (filter.createdFrom ? r.createdAt >= filter.createdFrom : true))
.filter(r => (filter.createdTo ? r.createdAt < filter.createdTo : true))
.filter(r => (kw ? r.searchText.includes(kw) : true))
.sort((a, b) => b.createdAt - a.createdAt)
.slice(0, filter.limit);
}
}
ここで言いたいこと😊✨
statusが指定されたら、最初からその箱(bucket)だけ見る- これがDBで言う インデックスで絞ってから取る のミニ版だよ🛣️💨
8) ハンズオンB:DBで“本物のインデックス”を貼る🗄️🚀
ここからは「Read側をSQLite等に置いた」想定での型だよ😊 (Read側は最適化しやすいから、DBの恩恵がモロに出る✨)
8-1) Prismaスキーマ例(一覧用テーブル)📋
model OrderListRow {
orderId String @id
createdAt DateTime
status String
totalPrice Int
itemCount Int
menuNamesJoined String
searchText String
@@index([status, createdAt])
@@index([createdAt])
}
@@index([status, createdAt])が「絞って並べる」に効く🛣️✨ (Prismaのindexは公式にこの書き方でOKだよ)(Prisma)
8-2) QueryService例(必要な条件だけDBに渡す)🔎
import { PrismaClient } from "@prisma/client";
const prisma = new PrismaClient();
type ListQuery = {
status?: string;
createdFrom?: Date;
createdTo?: Date;
keyword?: string;
limit: number;
};
export async function getOrderList(q: ListQuery) {
const keyword = q.keyword?.trim().toLowerCase();
return prisma.orderListRow.findMany({
where: {
...(q.status ? { status: q.status } : {}),
...(q.createdFrom || q.createdTo
? {
createdAt: {
...(q.createdFrom ? { gte: q.createdFrom } : {}),
...(q.createdTo ? { lt: q.createdTo } : {}),
},
}
: {}),
...(keyword ? { searchText: { contains: keyword } } : {}),
},
orderBy: { createdAt: "desc" },
take: q.limit,
});
}
9) キーワード検索をガチで速くしたいなら:FTS(全文検索)も選べる📚⚡
SQLiteには FTS5 っていう全文検索機能があるよ(公式)(SQLite) LIKE検索より大きいデータで強くなりやすい✨
超ミニ例(SQLイメージ)🧪
CREATE VIRTUAL TABLE order_list_fts USING fts5(orderId, searchText);
-- 検索
SELECT orderId
FROM order_list_fts
WHERE order_list_fts MATCH 'からあげ';
「FTSは難しそう…😵💫」ってなったら、まずは ① searchTextでcontains ② データ増えてきたらFTS でOKだよ😊✨
10) 最新事情メモ(2026の今っぽポイント)📰✨
- Node.js は近年、TypeScriptを“そのまま実行” できる流れが強いよ(erasableなTS構文ならOK)(Node.js)
- TypeScript は 5.9 が出ていて、
tsc --initの初期設定もより今風になってるよ(Microsoft for Developers) - Prismaも7系でパフォーマンス改善を継続してる(Read側を育てる時に相性良い)(Prisma)
- 2026年1月時点だと Node.js 24 系がLTSとして更新されてるよ(Node.js)
(※ここは“今の空気感”として押さえる感じでOK😊)
11) ミニ演習(手を動かすやつ)📝✨
演習1:一覧に「今日の注文だけ」フィルタを追加☀️
- createdAt の範囲条件(今日の0:00〜翌0:00)を作って検索してみよ!
演習2:「PAIDだけ」+「新しい順」で常に20件返す🏎️
- インデックスが効く想定の王道クエリ✨
演習3:searchText を賢くする🧠
- 「注文番号」「メニュー名」「ニックネーム」をまとめて
- 余計な空白を潰して
- toLowerCaseする(英字だけでも効果あり)
12) AI活用プロンプト(コピペでOK)🤖✨
① 検索パターン棚卸し
「注文一覧で想定される検索条件を、頻度が高い順に10個出して。インデックス候補もセットで提案して」
② Readモデル設計レビュー
「このOrderListRowのフィールド構成で、一覧表示と検索が速くなる?不足やムダがあれば指摘して」
③ 複合インデックスの順番相談
「status + createdAt の複合インデックスを作ると何が速くなる?逆順だと何が変わる?」
④ searchTextの作り方
「検索の漏れが減って、更新コストも低いsearchTextの生成ルールを提案して」
13) よくある落とし穴⚠️🐾(ここだけ注意!)
-
検索条件とインデックスが噛み合ってない → “絞る→並べる” の順で考えると当たりやすい😊
-
Readモデルに情報を詰めすぎる → 一覧に要らないものは持たない!✂️✨(必要になったら足す)
-
ページングの並びが不安定 → createdAtだけだと同時刻があり得るなら、
createdAt + orderIdみたいに安定キーも検討👍
次章につながる一言📣✨
検索が速くなると、次は 「集計も速くしたい📊🔥」 ってなるはず! 次は Read最適化②(集計)に進むよ〜!🎉